Database Partitioning with practical approach!
- Rohit Sharma

- Oct 17, 2021
- 7 min read
Hello Readers,
Hope you all are doing well! Today I m here with another interesting topic in the database i.e.; Partitioning. What is Partitioning? Why do we need partitioning?
We will cover all this stuff in this blog. Let' start the magic show.
Partitioning
Let's assume you have a table named "test" that has a "score" attribute and it contains almost 3 million rows. Now you wanna get that data which is having score=90,000. It's a simple select query you gonna simply write.
SELECT * FROM test WHERE id=90000It's simply gonna search and fetch the particular data having id=90,000. Everything is fine but if you see the work that the database gonna do internally here its needs to search and fetch the particular value against 3 million rows. Even you index the "score" attribute it's gonna take much more time because the more the search space the more it's gonna take time.
To optimize the same we can break down the table into smaller parts and tell the database that the value from this range to this range lies in this table and value from this table to this table lies in another table.
Types of partition
Horizontal Partitioning:- This is basically the most common type of partitioning in this basically you break down the rows by ranges (You can consider breaking the table by X-axis ). The range can be anything it can be your primary key, date attribute, serial number anything that can define your ranges. For example:- Let's take a table "users" having a very large number of rows suppose 4 million. Due to this much amount of data in the table the select query is taking much time. To optimize this we can break down our tables into smaller parts suppose there will be a table named users0_20000 which will contain all the rows whose value ranges from 10 to 20000 and suppose we have another table named users20000_90000 all the rows whose value ranges from 20000 to 90000. Now suppose we write something like "select * from users where id=20003" so instead of searching the whole 4 million rows the database gonna hit the table named "users20000_90000" because at the time of partitioning we have told the database about ranges so our search space will be small our query will be automatically faster.
Vertical Partitioning:- In this, you basically break down the column into small parts. (You can consider breaking the table by Y-axis ). This can be any column that contains a large amount of the dataset. For example:- Let's take a table "users" and it has attributes like "addresses", "phone_number", "email" and a "media". The data type of the "media" attribute is "blob".(Blob is mainly used to store your media like photos, videos, and other stuff in binary format). Suppose user A keeps uploading images and you keep appending the media data into the "media" attribute and whenever you gonna fetch the complete row for any particular id let's say "select * from users where id=9000". It's gonna fetch the data complete data but as we have seen our blob data is too much big. its gonna take more time than usual. You can say like I m gonna select a particular attribute instead of a wildcard query like "select id, name, email from users where id=9000". But here is the thing even you choose your attribute in select the database internally gonna fetch the complete page from HDD and its related data and after fetching it's gonna filter your selected attributes. We can optimize this issue by creating another table named "users_media" and bind it with the "users" table. In this case, the database gonna fetch the reference pages from the HDD of the "users_media" table bound with the "users" table, not the actual data until and unless you join both the tables. You must be thinking it's the kind of normalization we do regularly and managing relationships. Yes, it is kind of the same thing but in the case of the partition, you can partition the normalized table too.
There are different ways of partitioning a table.
Partition by range
Partition by Key
Partition by Hash
So we are done with the theory part lets start with the practical parts. Let's write down some magic and see how it works.
(Note: We will be using PostgreSQL database for further operations)
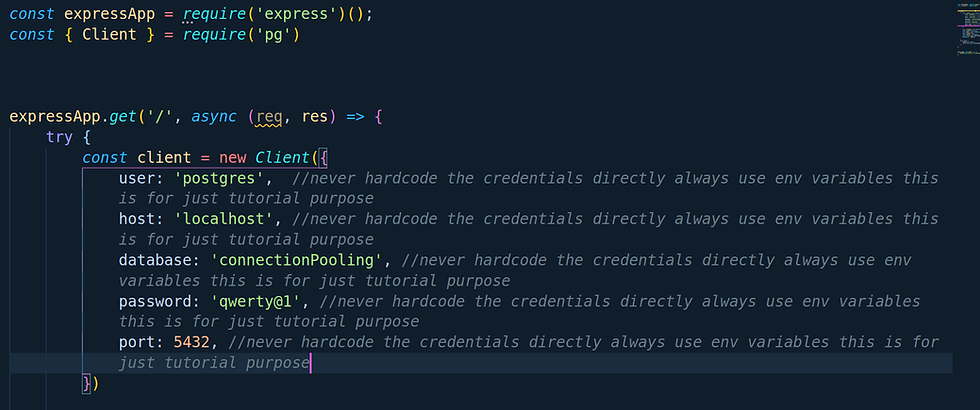
Let's quickly create a table named "test_data_table" which will contain all the data.
So just write our simple and beautiful query to create a table with two attributes "id" and "data".We will basically keep this table as our data storage.
create table "test_data_table"(id serial not null,data int not null); Once your table is created let's insert some data by using insert query.
insert into "test_data_table"(data) select floor(random()*100) from generate_series(0,10000000);Here we are simply first using random()*100 so basically it's gonna give the random values from 0 to 99 and we are wrapping the same under the floor function and we are getting these data from our dataset generate_series(0,10000000) which basically generate series of numbers from 0 to 10000000.10000000 After selecting we are going to simply insert into "data" attribute.
Let's quickly create our beautiful index over the "data" attribute.
create index on "test_table_data"(data)Now quickly check the count and table info if everything goes well or not.

So yeah we are done with this part. In this, we basically gonna perform horizontal partition so let's quickly create its parts.
create table "test_table_parts"(id serial not null,data integer not null) partition by range(data);So the above is simply create table statement only the addition thing is here is partition by range(data). We have used this basically to tell the database that hey buddy I m going to use the partition by range method considering the base attribute as "data".
After that let's split the tables.
Let's create a table having a range from 0 to 34 named "test_table_0035". Let's use a shortcut here.
create table "test_table_0035"(like test_table_parts including indexes);So this is the simply create statement here we have specified from where it needs to copy the table schema i.e.; test_table_0035 whether it needs to include indexes or not from the target table from where it's copying the schema.
Now let's quickly create two more tables like this
create table "test_table_3570"(like test_table_parts including indexes);create table "test_table_70100"(like test_table_parts including indexes);So we have created partitioned tables now define the ranges in the partition table to our base table so the values get inserted into its defined ranges.
alter table "test_table_parts" attach partition "test_table_0035" for values from (0) to (35);In the above statement we are performing some operations on our base table i.e.; "test_table_parts". Here we are saying to the base table "hey buddy you are not alone there are some of your parts present having some values. So meet your new part whose name is "test_table_0035" and this part will contain all the rows whose "data" attribute value lies between 0 to 34. (Note:- It always work as a start value to end value-1 same as an array index).
Let's create more partitions using the same above statement.
alter table "test_table_parts" attach partition "test_table_3570" for values from (35) to (70);alter table "test_table_parts" attach partition "test_table_70100" for values from (70) to (100);So we are dong with subparts creation of our table. let's describe any sub-part table and see what information we gonna get.

Voila! when we get info about our sub table its showing and telling us " hey there I m a subpart of table "test_table_parts" and the values which I contain is from 70 to 100"
Now let's insert values to our base table i.e.; "test_table_parts" from our master data table which we have created earlier i.e.; "test_data_table".
Let's write our beautiful insert query which will be copying data from our master data table.
insert into "test_table_parts" select * from "test_data_table";Let's understand what the above statement did, it's basically copies all the data from test_data_table and inserts it into test_table_parts.
Let's check if all data gets copied or not after insertion into "test_table_parts". We can do this by executing our COUNT query.

Here we go its the same number we get from "test_data_table". Let's check whether our partition is successful or not on sub-parts.

As we have runner our count and max aggregate query we can see the changes here let's take the case of "test_table_0035"
The count values showing around 3.5 million of data because remember we have created around 10 million of data which is a combination of numbers that lies between 0 to 99. So this sub-table consists of all those rows which lie between values 0 to 35 for the "data" attribute because we have repetitive values from 0 to 99 for 10 million times.
The max shows us value 34 because we defined the partition range from 0 to 35 as we know the partition works as a start value to end value-1.
Now let's create an index on every partition table for a faster read operation.

(Tip:- I m currently using PostgreSQL version10.18 but if you are using version 12 or above instead of creating an index on each individual sub-part table you can directly create on base table and it will automatically populate to its subpart ).
Let's run some beautiful queries and see if it's actually working.
explain analyze select data from test_table_parts where data=30;
Voila! If you closely see its actually querying and processing our "test_table_0035" table instead of the "test_table_parts" table because remember we have pushed all the rows between 0 to 34 into "test_table_0035"
Let's run another select query and check how its works
explain analyze select data from test_table_parts where data=82;
Voila! If you closely see it's actually querying and processing our "test_table_70100" table instead of the "test_table_parts" table because remember we have pushed all the rows between 70 to 99 into "test_table_70100".
If you face difficulty in understanding any technical terms which I have used here you can check my previous blog it's gonna defiantly help you out
That's all for this blog. Please do read, like, and share your feedback!
Keep Reading! Keep Learning!


Comments