In-Depth Explanation about Indexing in Databases (B-Tree v/s B+-Tree with examples)
- Rohit Sharma

- Sep 11, 2021
- 9 min read
Hello Readers,
Hope you all are doing well!
Today we are again here with the most common topic indexes you must use and read about this a lot. We gonna redefine in our own way. So let's have a closer look at this!
The first question which comes into our mind is what are indexes? Why do we need them? Should we create indexes in each and every table? What are the pros and cons of indexes?
We will cover all these things in this blog. Let's start the show ;-)
(Note:- We gonna use PostgreSQL Database as a reference and operations)
Suppose we have millions of rows and we need to find any record having name='Rohit' so what we gonna do we gonna scan pages(Hard disk drive pages) and each page gonna have some record we will be checking that if this particular page is having a record of name='Rohit' if yes then we gonna stop our searching otherwise we gonna go on and on until we found our record or we completed searching our table. This is known as a full table scan.
So this operation will be very slow. Does the next question arise how we can make this searching fast?
One way is to partition the table (can be vertical or horizontal) according to key and value like from id=1 to id=1000 will be in the first table and from id=10001 to 20000 will be in another table and so on and invoke multiple threads and those threads will be searching parallelly for the name='Rohit'. Hmm, this can work but if you see here its a very complicated process and require a lot of resource and management.
Here comes the indexing in the picture. Indexing is just a data structure that will help you to minimize your search space so that you don't need to do a full table scan.
A simple example if you take is a notebook. When you buy a notebook you must see the very first page named INDEX. Here's the sample image

Suppose we need to find the content having the title 'observation drawings' which is present 4th row from the beginning. What we can do we can check out each page and check if the title is stated as 'observation drawings'. Hmm but this will be a lengthy process but here we gonna take the help of our hero of this blog i.e.; INDEX. We just gonna search the tile and its specified page if we see in the above image the title 'observation drawings' is present on page number 4. So we will be just quickly jumping out on that page and get our content.
So yeah this is it. This is how indexing works it's just stored the key ranges along with page value and whenever you gonna search its quickly checks the index data structure and finds that page where your search record will be present.
So what data structure does the indexing used? It is mainly trees like binary trees ( the scary topic of data structure;-( ). The structure of the binary tree is like we have a value that will be acting as root node now the value which is lesser than the root node will be going to the left side and the value which is greater than the root node will be going to the right side. Let's see an example

Yeah, this is our eco-friendly(green color) binary search tree!
Lets dry run this tree suppose we need to find the value 6
We first start from the top which has a value of 8.
Now checking our value i.e.; 6 is lesser than or greater or equals than root node i.e.;8
Hmm its lesser so move out to left
Here we have the first node which has a value of 3
Now again checking out value i.e.;6 is lesser than or greater or equals than our first left node i.e.;3
Hmm it's greater so move out to right
Once you move to the right you again check the lesser, greater, or equals to our search value i.e;6.
So yeah it's equals to the same.
Finally, we have found out the search value
If we see here we almost eliminate half the search space(if you are lucky) in the above case like we don't need to go to the right subtree. But the problem with this tree is not every time balanced. Suppose from the above example if we take we have a root node having value 1 and then we are inserting successor value like 2,3,4,5 till 15 so all these successor values will be inserted in the right-hand side of the root because we know the property of the binary tree (greater will always go to the right). And now suppose we need to search value 15 so what you gonna do you gonna start from root i.e.;1 and keep searching at the right like value 2,3 and so on till you find value 15. Hmm,
so if we look at this closely this is a full table scan. We are searching each page like values 2,3 and so on till we find value 15.
If we look here the only flaw that we are seeing with the above data structure is that it's not self-balancing. We need something which gets self-balanced automatically.
Let's call our savior the B-Tree.
The main property of B-Tree which makes it different from the binary tree is that "B-Trees are self-balanced". As you keep inserting the values the B-Tree will keep balancing itself. But, B-Tree says I will keep balancing your values whenever you gonna insert into table or database but I will charge you some cost because once a legend says "If you are good at something never do it for free ;-)" (Heath Ledger)
What is the cost here? The cost is the rebalancing as you keep writing into the table the B-Tree will keep rebalancing itself so that we can search or read quickly from our table. By this, we can conclude that our reads gonna be fast and write gonna be Lil bit slow because of the cost of rebalancing.
You can check this by using this website it is the most popular one it will provide you a visual representation of how actually B-Tree rebalance itself when values keep getting inserted constantly
B-Tree Visual Link URL:- https://www.cs.usfca.edu/~galles/visualization/BTree.html
Let's see an example here

Here I have inserted values from 1 to 8. now I m going to insert values 9,10,11 let's see how it gonna rebalance itself.

If you see the above image it has splits and rebalanced itself and changes the structure from the previous image. Try by yourself to the link which I have provided above you will love it.
Let's discuss the cons of using B-Tree as an index. The first cons of the B-Tree structure are they store values instead of page references if you see the above image we having (4,8) which is our root node but if you look closely it's a page(Hard Disk Drive Page) which is storing keys and values. Don't you think we will be able to store more data if we have only references or keys instead of saving keys and values both?
Another con of B-Tree is the more disk I/O(Input and output operation) while searching. Let's see it with example suppose from the above structure we need to search values 2,7 and 9 in a single go.
We gonna start from root (4,8), compare and go to the left of 4, and find our value i.e.;2.
Now again we gonna start from the root and compare we see it's between 4 and 8 (the value 7 is between 4 and 8).
So we gonna go to root node 6 then we again compare and move to the right and we find the value 7
Now let's search our final value i.e.; 9
Now again we gonna start from the root and compare we see it greater than our root node
We gonna move to the right of the root node
We find a node having a value of 10 again we compare and check and we move to the left of the node
And yeah here we found our last search value i.e.; 9
If you see closely we need to perform three disk I/O operations to find out three values and we need to start from again for searching any value. Just imagine we need to find 10 values in one go so there will be like 10 disk I/O operations which gonna cost more operations.
Hmm, so how are we gonna overcome with above issues. Let's call our another avenger B+-Tress.
B+-Trees are the same as B-Trees the only difference is the B+-Tree only stores the keys(except at leaf nodes), not the values, and all the values get stored at only leaf nodes(The node without any children). But we need to duplicate the keys at the leaf node to bind it with values.
You can check this by using this website it is the most popular one it will provide you a visual representation of how actually B+-Tree stored the keys and values at leaf nodes
B+-Tree Visual Link URL:- https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
Let's see an example

In the above image, I have inserted the value 1,2,3 and 4. If you see at the leaf node it has duplicated the keys at the left node. Now I m gonna insert more values lets see the same.

So in the above image, I have inserted the values 5 and 6. If you see again the keys have been duplicated at leaf nodes. (If you learn how these balancing and operations are working in B-tree and B+-Tree do let me in comments I will write a blog for the same.)
Let's do our favorite searching operation now suppose we need to search 1,4 and 6 in one go in B+-Tree
As usual, we gonna start from the root node i.e.; 3
Then we gonna compare with our first search value i.e;1
We compare and we find lesser we move to left
Again we compare and we find lesser value again we move to left
Woo hoo! we find our first search value i.e;1
So now let's pick the search value 2
Do we need to again jump to the top and again need to that lengthy operation?
Nope, we don't need to do as we can see the keys at the leaf node are in sorted order along with the values
So we just need to move in the right direction from the leaf node having a value of 1
So we start moving and searching for the value 4.
So the last second node in the horizontal direction we have node 4.
Let's pick our final value i.e.; 6
So again the question comes to our mind "Do we need to again jump to the top and again need to that lengthy operation?"
Nope we don't need we will just proceed forward from our last reached value i.e.;4
We again move to the next and hell yeah! we found our last value too.
If you see the above cost of the above operation we only require a single disk I/O operation to find all three values.
The only cons B+-Tree is having the cost of duplication at the leaf nodes of keys to bind with values. But in my opinion, this cost is very little. So what's your opinion regarding this? Do let me know in the comments will love to read your opinion and feedback!
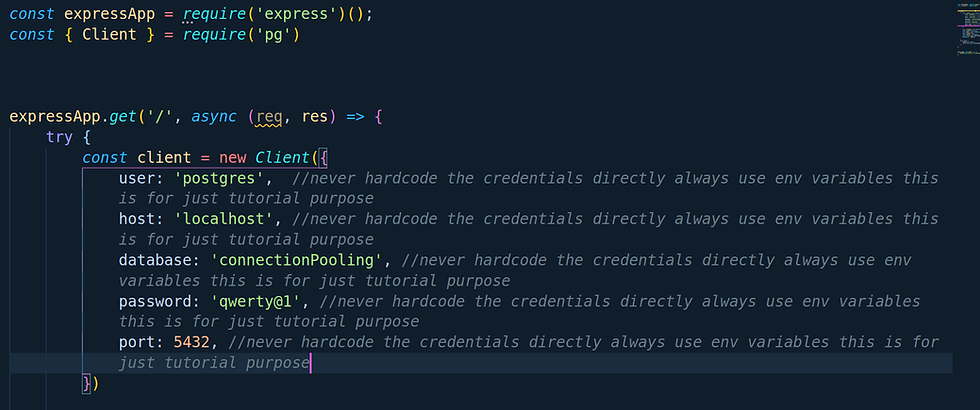
Let's quickly see a quick indexing operation and how it's going to help us! We have a table named as users and we have two attributes one is id and another is random_numbers
users
id (serial primary key) | random_numbers (integer)We are storing almost 10,000 records in this table.

Now we gonna perform our SELECT query but with EXPLAIN ANALYZE statement(This is a basic SQL statement that executes the query and shows us how much the operation cost).

In the above operation, we try to find a value of 7544. We got some weird output statements. Don't worry we gonna discuss the same!
The first line tells us the database did the sequential scan and used one loop to find the value 7544
The second line tells us the database filter out our searched value
The third line tells us the count of an unwanted searched value that doesn't match our search value.
The fourth line tells us the Query Planning time (Whenever we run any query there is a query plan which decides what will be the optimized way to execute the query)
The last line tells the total amount of time to perform the select operation
Let's optimize our search space and quickly create an index over attribute "random_numbers"

Ita a very basic syntax
"CREATE INDEX (any logical index name) ON (table name) (column or attribute name)"
(By default index in PostgresSql is B-Tree )
Lets again re-run our same SELECT query with EXPLAIN ANALYZE statement

In the above operation, we again try to find a value of 7544. We got some weird output statements. Don't worry we gonna discuss the same!
The first line states that the database did the Heap Scan on the table with a single loop
The second line states that while scanning it checks for the search value i.e.; 7544
In the third line, it filtered out the blocks(page on the Hard disk drive) which satisfy our search value
Now in the fourth line the database using the index which we have created earlier i.e; "indx_random" and try to locate the page where our search value will be exists
Now in the fifth line, the index is checking the condition "whether its matching our search value or not"
The fourth line tells us the Query Planning time (Whenever we run any query there is a query plan which decides what will be the optimized way to execute the query)
The last line tells the total amount of time to perform the select operation
Finally! if you compare the select query with the index and select query without the index you will notice the difference of time. Select with index takes up to 0.150ms and Select without index takes up to 2.918ms.
That's all for this blog. I will meet soon with you all with another topic!
Stay Safe and Healthy! Keep Coding!


Comments