Database Cursors with a practical approach
- Rohit Sharma

- Jan 1, 2022
- 4 min read
Updated: Jan 1, 2022
Hello Folks,
Hope you are doing well and wish you a very happy new year!
Today I m here with another interesting topic which is "Database Cursors".'
We gonna cover "what is cursor when we need to use cursor, pros, and cons of cursors"
So let's start the show
"Cursors are basically stateful special variables that hold query result set and provide inbuilt functions via which we can get the stored values such as "fetch" keyword".
Let's take an example and see how these cursors work and when we can use these.
Suppose we have a table named "test_db" and it's having the following number of rows.
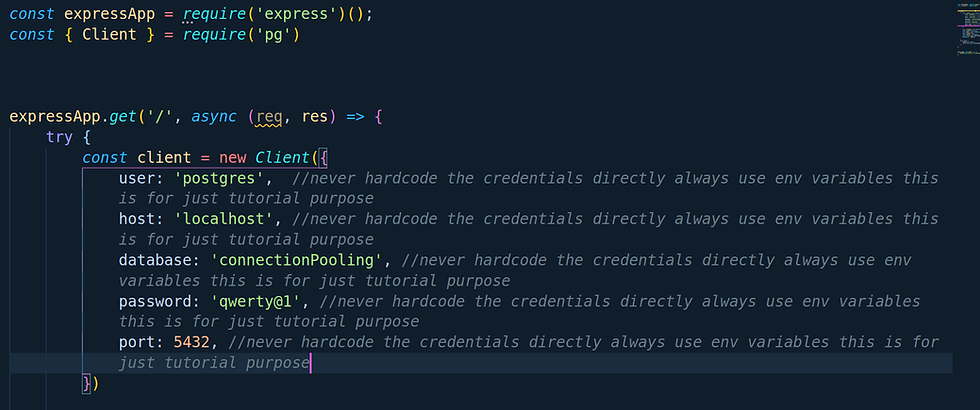
Note:- We will be using the PostgreSQL database for further operations.


If we see in the above explain analyze statement it's taking almost half a second to fetch the id attribute from the table. And as our table data gets exceeded the query time will also exceed simultaneously.
If we try to work on this huge number of rows in one go it's gonna be very costly so what we can do is break down the number of rows into small chunks and start working on it instead of fetching all the rows in one go.
For this, we can declare a cursor via following the below commands.

Let's break down each statement and analyze what happens.
begin:- Database cursors always execute in a transaction block. So to start the transaction block we have written begin statement.
declare c cursor for select id from test_db where id between 10 and 100:- In this statement, we are declaring a cursor with the name c and that cursor c is going to save the results which will be coming from statement(select id from test_db where id between 10 and 100 i.e.; we are selecting the ids between 10 and 100)
fetch c:- As in the second statement we have stored the result set in cursor c so to fetch the value we have written fetch c. As we write more fetch c we can see we are getting new values from the result set.
If we see here we need to write fetch c statement again and again to get the next result value which is very much annoying so to remove this dependency we can write a stored procedure for the same and automate the process. Let see how we gonna do it.

Note:- Stored procedures are supported by PostgreSQL after version 11 before that procedure were written as a function.
Let's see what we have done here let's break down each statement and see
create or replace procedure cursor_function(param_start_range int,param_end_range int) language plpgsql as $$:- To create any procedure we need to write the create or replace procedure statement and after that, we declare procedure name and in brackets, we are defining the parameter which we will be going to pass in this procedure along with datatype it is same as the normal function we write in our traditional programming language. And after this we are defining the language in which we are going to write procedure i.e. plpgsql
declare:- This is the declaration block of the procedure and in this, we declare all the variables which we gonna use in the procedure further. So here we have declared cursor with the name as c.
c cursor for select id from test_db where id between param_start_range and param_end_range:- In this statement, we are storing all the result set from which lies between parameter ranges from param_start_range and param_end_range.
begin:- This statement indicates the beginning of the transaction block if you wanna learn more about transactions you can visit this link.
for cursor_data in c:- Here we have started a loop over cursor c with the variable named cursor_data. The cursor_data will hold all the values available in result set c.
LOOP:- this declares the starting of the loop block.
raise notice 'details are %',cursor_data.id:- This statement is mainly used to print the data for each iteration same as console.log in javascript, print in C, and count in C++. As we know from the above statement the cursor_data is holding all the data in each iteration and we want to print the value id only so we have used "cursor_data.id"
END LOOP:-this declares the ending of the loop block.
commit:- This indicated the completion of the transaction block.
end;$$:- This indicates the completion of the stored procedure.
call cursor_function(1,10):- To call any stored procedure we need to first write the call and then the procedure name. Here our procedure name is cursor_function and along with two parameters 1 and 10.
So this is just a small introduction about the stored procedure and how they work. If you want to learn more about stored procedures do let me know in the comment section.
There are mainly two types of cursors (I have given a small introduction in this section if you wanna know more about it let me know in the comment section)
Client-side cursor:- This type of cursor defines on the client-side using via ORM's like pg-promise in javascript,psychopg2 in python.
Server-side cursor:- This type of cursor defines at the database level just as we have seen in the above example. So on the client-side, we just use already defined cursors at the database level and perform our operation.
Let's see the pros and cons of database cursors.
PROS
Saves memory on the client-side:- When we are working with the very large tables and if we gonna try to fetch all the rows at once it's gonna take a huge amount of network bandwidth and memory too. So in this case we can break it down into a bunch with the help of the cursor and process it.
Streaming:- You can stream to multiple web socket connections by breaking down large table rows into small rows to multiple connections.
Can be used in paging and writing procedures:- As we have seen in the above procedures we can do paging and use cursors in procedures. If you wanna learn about paging in the database you can visit this link.
CONS
Stateful nature:- As in our first statement we have seen that cursors are stateful and can be only run under transaction block. It means there must be a memory consumption at the database and overhead of transaction management.
Long-Running transaction:- As we know cursors work under transaction blocks if we have a long-running transaction along with cursors it's gonna impact other users to do useful operations on the particular table.
So that all for this blog please do write your feedback or anything I missed.
Once again wish you a very happy new year!
Keep learning! Keep querying!


Comments